比如要找 INSERT INTO `ims_ewei_shop_member`
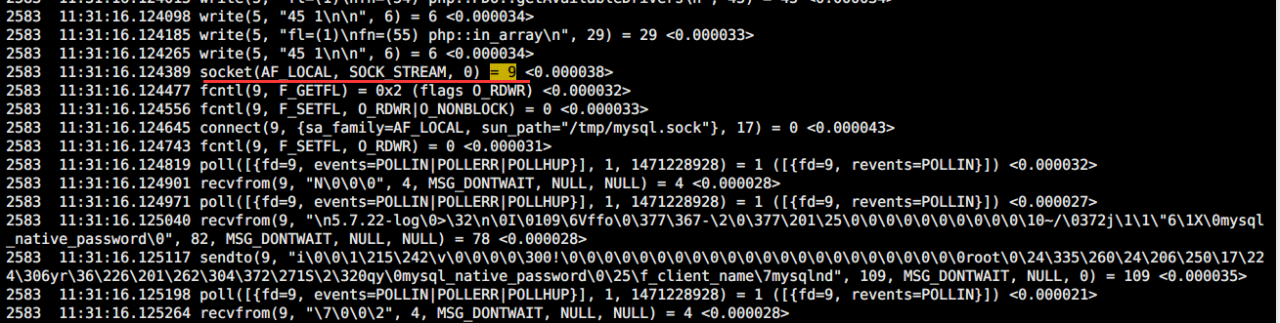
1.strace 抓取所有进程并保存结果
strace -v -s 65536 -tt -T $(pidof “php-fpm” | sed ‘s/\([0-9]*\)/-p \1/g’) -o a.txt
[……]
[……]
研究一些随机的因素,主要是讲究效率问题。
语句一:
复制代码
MYSQL手册里面针对RAND()的提示大概意思就是,在 ORDER BY从句里面不能使用RAND()函数[……]
原大众点评的订单单表早就已经突破两百G,由于查询维度较多,即使加了两个从库,优化索引,仍然存在很多查询不理想的情况。去年大量抢购活动的开展,使数据库达到瓶颈,应用只能通过限速、异步队列等对其进行保护;业务需求层出不穷,原有的订单模型很难满足业务需求,但是基于原订单表的DDL又非常吃力,无[……]
1.看手册
The DATE type is used for values with a date part but no time part. MySQL retrieves and displays DATE values in 'YYYY-MM-DD' format. The supp[……]
查询速度慢的原因很多,常见如下几种:
1、没有索引或者没有用到索引(这是查询慢最常见的问题,是程序设计的缺陷)
2、I/O吞吐量小,形成了瓶颈效应。
3、没有创建计算列导致查询不优化。
4、内存不足
5、网络速度慢
6、查询出的数据量过大(可以采用多次查询,其他[……]